



Imaginez que vous disposiez d’un grand tableau de données : en ligne, des individus (ou des observations), en colonne, des variables qui les caractérisent. Le tableau est grand, il comporte de nombreuses lignes. Il pourrait aussi comporter de nombreuses colonnes, mais ce n’est pas notre problème dans un premier temps. Et vous n’avez aucune connaissance a priori sur la structuration des observations.
Des groupes de points
À l’extrême, et parce que c’est plus facile à visualiser, considérons qu’il ne comporte que deux colonnes, qu’elles concernent deux variables quantitatives (qui se mesurent), appelées V1 et V2. Une observation représente donc un point dans ℝ2. Afin de bien appréhender ces données, il est possible de résumer chacune des variables (moyenne, écart-type) et de les représenter sur une figure, V1 sur l’axe des abscisses et V2 sur celui des ordonnées.
Une information très intéressante se dégage de l’exemple du haut ‒ on y voit trois groupes très distincts ‒, tandis que dans celui du bas, tout semble ne former qu’un seul amas. L’exemple du milieu est intermédiaire : on pourrait définir trois groupes, mais les frontières ne sont pas claires.
.png)

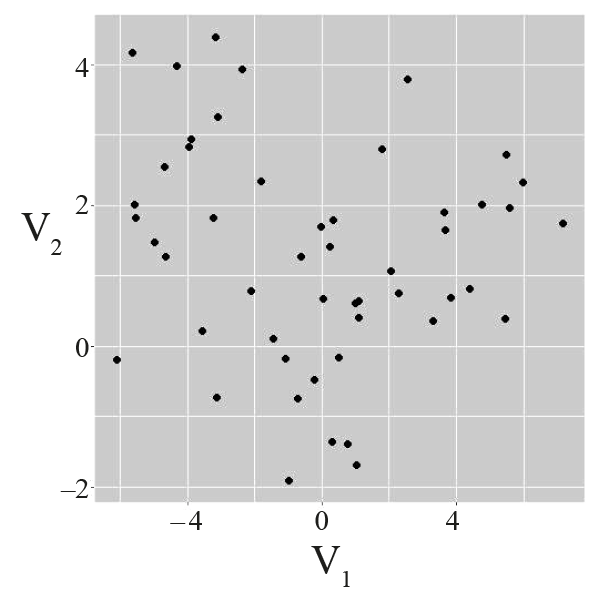
Un ordinateur pourrait-il automatiquement définir ces groupes à partir du tableau de données ? Peut-il même aller plus loin que l’humain en décidant du nombre de groupes et de leurs contours dans les cas où ils ne sont pas visuellement évidents et où il y a de nombreuses variables ?
La réponse est oui ! C’est l’objectif des méthodes de classification automatique, ou classification non supervisée, ou encore clustering en anglais. Contrairement à ce qui se passe pour la classification supervisée, l’objectif est ici de grouper les éléments selon des classes non données a priori (voir encadré). Les objectifs du clustering sont donc de proposer des méthodes pour :
(1) former des groupes d’observations (ou classes, ou encore clusters) fortement semblables à l’intérieur d’un groupe, et les plus différentes possibles entre les groupes ;
(2) caractériser les observations d’un groupe par un comportement moyen ;
(3) choisir le nombre de groupes.
Ces méthodes font partie du vaste ensemble des techniques d’apprentissage automatique.
Le clustering permet donc de découvrir une structuration en classes d’un ensemble de données. En général, les classes forment une partition des observations, c’est-à-dire des parties disjointes deux à deux et dont l’union est l’ensemble total.
Classification non supervisée ou classification supervisée ?
L’apprentissage machine (machine learning) permet à un ordinateur d’optimiser une tâche à partir d’observations qui lui sont fournies.
Quand la tâche est la prédiction d’une des variables de l’observation, l’apprentissage est supervisé. On dispose par exemple d’un ensemble d’images étiquetées (différentes espèces d’animaux, typiquement) : une observation est une image, ses variables, les couleurs de chaque pixel ainsi que l’étiquette. À partir de cet ensemble d’images, le programme d’apprentissage optimise une fonction qui permet de prédire l’étiquette en fonction des valeurs des pixels, en minimisant le risque de faire une erreur d’étiquetage. Cet apprentissage est supervisé par les étiquettes de l’ensemble initial d’images.

En classification non supervisée, il n’y a pas de variable privilégiée à expliquer ou à prédire permettant de superviser l’apprentissage. L’apprentissage est dit non supervisé. Toutes les variables jouent le même rôle et le but est d’essayer de découvrir directement une structure dans ces données.

La langue anglaise fait bien la différence entre ces deux types d’apprentissage, appelant clustering le cas non supervisé et classification le cas supervisé.
Cette méthodologie est très utilisée en pratique. En marketing, on segmente la clientèle ‒ des milliers, voire millions de clients pour des centaines de variables (les caractéristiques des clients) ‒ afin de préparer des campagnes marketing spécialisées pour chaque segment. En biologie, on regroupe des gènes qui ont des comportements communs d’expression. En imagerie médicale, on délimite automatiquement des zones d’apparence homogène d’un résultat de scanner ou d’IRM. En géographie, on détermine automatiquement différentes zones de culture à partir d’images satellites (ici, on cherche à regrouper des pixels qui ont des couleurs similaires). Le secteur de l’énergie l’applique pour le suivi de consommation électrique afin de déterminer des profils types de consommation. En analyse textuelle, on groupe automatiquement des textes de thèmes similaires sans définir a priori ces thèmes. C’est d’ailleurs un autre avantage du clustering : si un document répond à une requête, tous ceux de son cluster sont susceptibles d’être également intéressants pour cette requête. On retrouve ce principe pour les préconisations des plateformes vidéo.
Notion de (dis)similarité
Le partionnement des observations en K classes C = (C1, C2… CK ) doit permettre de définir des clusters formés d’observations les plus similaires possibles. Il est donc nécessaire de définir la notion de « similarité ». En général, on travaille plutôt avec son contraire, la dissimilarité, qui est une relation positive et symétrique.
La dissimilarité
Soit E l’espace auquel appartiennent les observations (par exemple, E = ℝp si les observations possèdent chacune p caractéristiques).
Une dissimilaritéd est une fonction de E×E dans ℝ+ telle que :
d(x, x) = 0 pour tout x de E,
d(x, y) ≥ 0 pour tous x et y de E,
d(x, y) = d( y, x) pour tous x et y de E.
Sur la première des trois figures, notre œil a utilisé naturellement la distance euclidienne pour comparer les observations. Une distance possède une propriété supplémentaire, celle de l’inégalité triangulaire, qui n’est pas nécessaire pour définir une dissimilarité.
Le choix de la dissimilarité a bien sûr une influence sur le résultat du clustering. On utilise très souvent la dissimilarité égale au carré de la distance euclidienne, et c’est ce qui sera fait ici. On peut ensuite étendre la notion de dissimilarité entre deux observations à celle de dissimilarité interne d’un sous-ensemble d’observations Ck , notée W(Ck ), moyenne de la dissimilarité de tous les couples d’observations de Ck . À un facteur multiplicatif 2 près, la dissimilarité interne du sous-ensemble est l’inertie de ses éléments par rapport à son centre de gravité. On définit enfin la dissimilarité interne d’une partition C des individus, W(C), appelée dissimilarité intra-clusters, comme étant la somme des dissimilarités internes des sous-ensembles qui la constituent :
avec
Dans cette définition ne sont comptées que les dissimilarités à l’intérieur des classes, pas celles d’observations entre classes. Ainsi la dissimilarité intra-clusters de tout l’ensemble (quand on n’en fait qu’une seule classe) est supérieure à la somme des dissimilarités internes des classes d’une partition.
Parmi toutes les partitions possibles, il s’agit maintenant de trouver celles réalisant l’objectif de minimisation de la dissimilarité intra-clusters, c’est-à-dire minimisant la somme des inerties internes des clusters de la partition, ou encore minimisant la distance de chaque observation au centre de gravité de sa classe.
Si l’on ne fixe pas le nombre de clusters K, et si les n observations sont différentes, ce qui est en général le cas quand les variables sont quantitatives, la solution est facile : prendre la partition de taille n, sa dissimilarité intra-clusters étant nulle.
Mais on n’a alors pas rempli l’objectif de regrouper des observations qui se ressemblent !
Dans un premier temps, on fixe donc cette recherche pour une taille de partition donnée K.
L’algorithme des K-moyennes
Une fois fixés le choix de la dissimilarité entre deux observations (dans la suite, le carré de la distance euclidienne) et le nombre de classes K, le problème de clustering s’apparente au problème d’optimisation suivant :
Chercher une partition C = (C1, C2… CK ) minimisant le critère de l’inertie intra-clusters W(C) parmi toutes les partitions à K classes.
Lorsque que le nombre d’observations est faible, on peut calculer l’inertie intra-clusters de chaque partition possible et obtenir ainsi celles qui en possèdent la plus faible valeur.
Mais le nombre de partitions augmentant exponentiellement avec le nombre d’observations (voir encadré), la recherche exhaustive devient rapidement impossible à réaliser.
Attention à l’explosion combinatoire
Le nombre de partitions en K classes d’un ensemble de n éléments est équivalent à
Kn / K! lorsque n tend vers l’infini.
Ainsi, par exemple, le nombre de partitions à K = 3 clusters dans un ensemble de
n = 10 éléments s’élève à environ 8 × 10 46.
Il faudrait ainsi 1033 années pour étudier toutes ces partitions pour un ordinateur sachant en traiter un million par seconde !

Mais tout n’est pas perdu ! En effet, un algorithme astucieux garantit, à partir d’une partition initiale quelconque, de converger efficacement vers un minimum local du problème. Cet outil providentiel est l’algorithme des K-moyennes (ou K-means), proposé la première fois en 1957 par Stuart Lloyd (1923‒2007), ingénieur américain aux laboratoires Bell.
En voici le principe expliqué en utilisant l’analogie d’une foule. Des participants se sont réunis sur une place (ce sont les points sur les figures en début d’article). Vous êtes l’organisateur et vous ne disposez que de trois haut-parleurs multidirectionnels pour diffuser les messages. Votre objectif est de placer les haut-parleurs de façon à ce qu’ils soient le plus éloignés les uns des autres pour limiter les interférences, tout en permettant aux participants d’être en moyenne le plus proche possible de l’un d’entre eux. Les participants eux-mêmes ne bougent pas pour éviter les mouvements de foule. Vous commencez par placer les haut-parleurs au hasard (étape 1), par exemple en les donnant à trois participants, puis vous affectez à chaque participant le numéro du haut-parleur le plus proche (étape 2). Vous avez ainsi défini trois groupes de participants. À la suite, vous déplacez chaque haut-parleur au centre de gravité de chaque groupe (étape 3). La position des haut-parleurs peut ne plus correspondre à la position d’un participant. Ayant déplacé la position des haut-parleurs, certains participants peuvent se trouver plus proches du haut-parleur d’un autre groupe. Vous recommencez donc l’étape 2 d’affectation aux participants du numéro du haut-parleur dont ils sont le plus proches, puis l’étape 3 de déplacement des haut-parleurs ; vous recommencez les étapes 2 et 3 jusqu’à ce qu’aucun déplacement n’améliore votre critère.

L’algorithme est assuré de converger en un nombre fini d’itérations, puisque le nuage de points est fini.
L’algorithme des K-moyennes implémente une stratégie gloutonne (à partir d’une situation initiale, il avance rapidement vers un minimum local), mais il est sous-optimal, puisqu’il ne garantit pas d’obtenir le minimum global. Il est alors rejoué plusieurs fois à partir de positions initiales différentes, et la partition donnant la plus faible dissimilarité est retenue. Ceci ne garantit toujours pas d’obtenir le minimum global, mais donne un résultat plus efficace et bien meilleur que la comparaison d’un nombre donné de partitions.
La méthode des K-moyennes n’est qu’une méthode parmi de nombreuses autres méthodes de clustering ; ses rivales sont la classification hiérarchique ascendante, les méthodes spectrales, ou encore les méthodes par densité, pour n’en citer que quelques-unes. Chacune a ses avantages et ses inconvénients suivant la conformation du jeu de données, rappelant la difficulté inhérente d’une méthode d’être non supervisée et le fait qu’il n’existe pas, pour ces problématiques, de « méthode universelle ».