

Quel que soit le domaine auquel ils sont confrontés, les statisticiennes et statisticiens essaient souvent de trouver des régularités, des ressemblances entre les individus étudiés pour simplifier une population en créant des groupes homogènes au sein de celle-ci : groupes de consommateurs au comportement semblable en marketing, classification d’images ou de zones d’images en imagerie médicale, détection de thèmes dans un grand corpus d’articles de journaux…
Il est possible de partir directement de la description des données pour trouver les individus « les plus semblables » (voir par exemple la méthode des K-moyennes dans l'article « La classification automatique »). Mais il est aussi possible d’analyser les données à travers un modèle statistique (voir encadré), modèle qui prend en compte le fait qu’une population observée provient en fait de plusieurs sous-populations différentes qui ont été mélangées : c’est le modèle de mélange.
Modélisation et clustering
Regardons les données de la figure ci-après. Si les individus représentés par les points ont été choisis au hasard dans une population, ces données définissent un échantillon indépendant et identiquement distribué de n observations en deux dimensions (par exemple, l’âge et le revenu) x1 ∈ ℝ2, x 2 ∈ ℝ2… xn ∈ ℝ2.
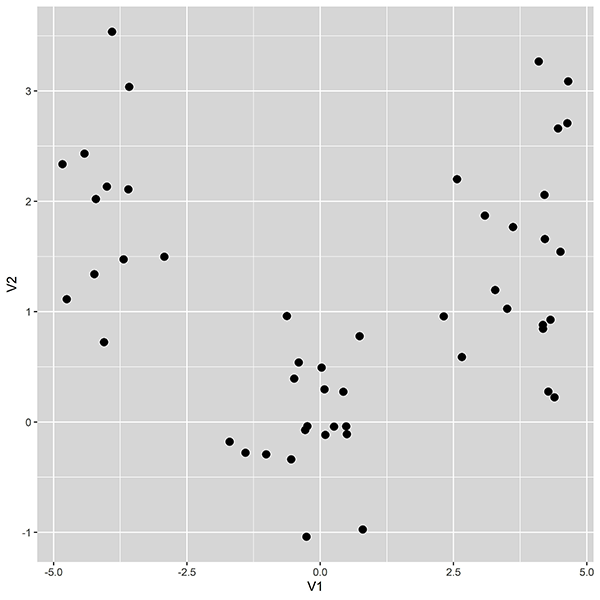
On y voit K = 3 groupes d’observations, de ... Lire la suite